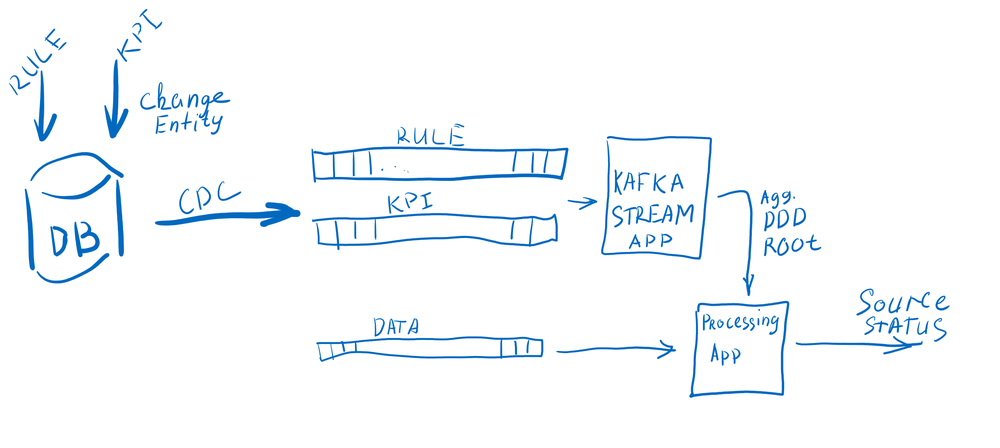
Our team is developing a network monitoring system, a solution similar to CISCO's openSOC. The data from network sensors consume the corresponding Kafka topic. Stream data processing based on Spring Kafka + Kafka Stream solutions. In the base case, the monitoring system should detect unexpected events or anomalies and spikes in the network activity, etc. In a general context, anomaly detection is any method for finding events that don’t conform to an expectation. In our days using thresholds, heuristics remains a reliable way of detecting anomalies and is easy to implement. How do we set the threshold? Could some users require a higher threshold than others? How frequently do we need to update the threshold? Could an attacker exfiltrate data by taking over many user accounts, thus requiring a smaller number of accesses per account? Let's take a look at the pros and cons of some of the approaches our team tried to implement.
Threshold values for network monitoring store in the Postgres database. There are several options for processing data according to thresholds:
- Use event model.
- Use Shared Database and do a scheduled query.
We choose the first option as it involves less load on the database as users rarely change rule settings for monitoring. There are several approaches for implementing event stream from a database:
- Write your own producers in a monolith, then find all places in the code where the application interacts with the database. Add code that produces events in the corresponding Kafka topic. If you have a good monolith architecture, with a dedicated repository layer, you can easily do this. But legacy won't be Legacy if there's good architecture there. So this option is also very complicated and time-consuming.
- Use out-of-the-box solutions to integrate the database and Kafka. You can use the Kafka Connect framework.
We tried to implement both approaches. But finding all the places in the code is not easy. Cascading data changes in the Postgres database left this solution behind. After all, we tried to use Kafka-connect, it is a better solution for our task.
There are several types of connectors.
JdbcSourceConnector - based on database's JDBC driver. This kind of connector makes a scheduled query to the database and increases a load on the database.
DebeziumPostgresConnector - connector makes a great thing: connect to the database cluster as a logical replica and read WAL. Based on it, our apps do not increase the load on the database.
And obviously, we choose a DebeziumPostgresConnector. Let's describe each step to deploy debesium in Kafka-connect.
Deployment
- Install plugging for Postgresql wal2json
sudo apt-get install postgresql-12-wal2json
- Add configuration in postgresql.conf
# MODULES
shared_preload_libraries = 'wal2json'
# REPLICATION
wal_level = logical
max_wal_senders = 1
max_replication_slots = 1
- Add Debezium Postgresql connector
mkdir /opt/connectors
cd /opt/connectors
wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-postgres/1.7.2.Final/debezium-connector-postgres-1.7.2.Final-plugin.tar.gz
tar -xvzf debezium-connector-postgres-1.7.2.Final-plugin.tar.gz
- Change connector configuration
nano /opt/kafka/config/connect-distributed.properties
- Set path for debezium connetor plugin
plugin.path=/opt/connectors
- Run connector
nohup ./bin/connect-distributed.sh ./config/connect-distributed.properties &
- Check plugin. We should see applied plugin list
dev@dev:/opt/kafka$ curl -s localhost:8085/connector-plugins | jq
[
{
"class": "io.debezium.connector.postgresql.PostgresConnector",
"type": "source",
"version": "1.7.2.Final"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"type": "sink",
"version": "2.7.0"
},
{
"class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"type": "source",
"version": "2.7.0"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector",
"type": "source",
"version": "1"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector",
"type": "source",
"version": "1"
},
{
"class": "org.apache.kafka.connect.mirror.MirrorSourceConnector",
"type": "source",
"version": "1"
}
]
## Change Postgresql configs
Add user, grant permissins on replica schema.
```sql
CREATE USER debeziumreplica WITH password 'debeziumreplica' REPLICATION LOGIN;
GRANT ALL ON database debeziumdb TO debeziumreplica;
GRANT USAGE ON SCHEMA debezium TO debeziumreplica;
GRANT SELECT ON ALL TABLES IN SCHEMA debezium to debeziumreplica;
GRANT SELECT ON ALL SEQUENCES IN SCHEMA debezium to debeziumreplica;
Create connector
curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/entity/config \
-d '{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"plugin.name": "wal2json",
"key.converter": "org.apache.kafka.connect.converters.IntegerConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "debeziumreplica",
"database.password": "debeziumreplica",
"database.dbname" : "debeziumdb",
"database.server.name" : "debezium-replic",
"decimal.handling.mode" : "string",
"transforms": "ExtractId",
"transforms.ExtractId.type" : "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.ExtractId.field" : "id",
"transforms.ExtractId.predicate" : "IsID",
"predicates" : "IsID",
"predicates.IsID.type" : "org.apache.kafka.connect.transforms.predicates.TopicNameMatches",
"predicates.IsID.pattern" : ".*(debezium\\.threshold)",
"publication.autocreate.mode" : "filtered",
"snapshot.mode" : "always",
"table.include.list": "debezium.threshold"
}'
Check created connector
curl -s -XGET "http://localhost:8083/connectors/" | jq '.'
Check output topic for events
curl -s -XGET "http://localhost:8083/connectors/entity/topics" | jq '.'
Later, in other posts, we will see how machine learning techniques can help switch to data-driven solutions for detecting anomalies.